LlamaFactory 使用教程:轻松实现大模型微调
各位朋友,今天我必须、一定要、强烈地安利一个神奇的工具——LlamaFactory!如果你和我一样,对微调大型语言模型充满热情,但又被各种复杂的命令行参数和环境配置搞得头大,那么请你务必认真看完这篇文章。因为,它真的会让你尖叫!
我这篇文章将理论结合实践来写,通过两个具体步骤来展示 LlamaFactory 的强大:
- 最快速地跑一个最简单的 DPO,体现它的易用性
- 使用本地模型和本地数据进行 DPO,体现它的定制性
初见 LlamaFactory:惊艳的第一印象
我之前也尝试过一些微调工具,要么就是配置起来像解一道高数题,要么就是界面简陋得让人想砸键盘。但是,LlamaFactory-CLI WebUI 的出现,简直就像一道耀眼的光芒,瞬间照亮了我略显昏暗的 AI 炼丹之路!
让我们从最简单的安装开始:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch]"
安装完成后,只需一行命令就能启动这个神奇的界面:
llamafactory-cli webui
打开浏览器,映入眼帘的界面让我惊呆了!
简洁明了的布局瞬间让人心情舒畅,各种参数选项排列有序,色彩搭配也恰到好处,完全没有那种”工程师风格”的冰冷感。这绝对是我见过最漂亮的 CLI WebUI 之一,用起来赏心悦目,效率都感觉提升了不少!
DPO 训练实战:从理论到实践的完美演绎
别看界面漂亮,功能可一点都不含糊!我马上开始了一次实战训练,选择了最简单但也最能体现特点的配置:
- 模型:
Qwen/Qwen-1_8B(轻量级但效果不错的中文模型) - 数据集:
hh_rlhf_en(内置的人类反馈数据集) - 训练方法:DPO(Direct Preference Optimization)
点击”开始训练”后,眼前的画面让我感动得想哭:
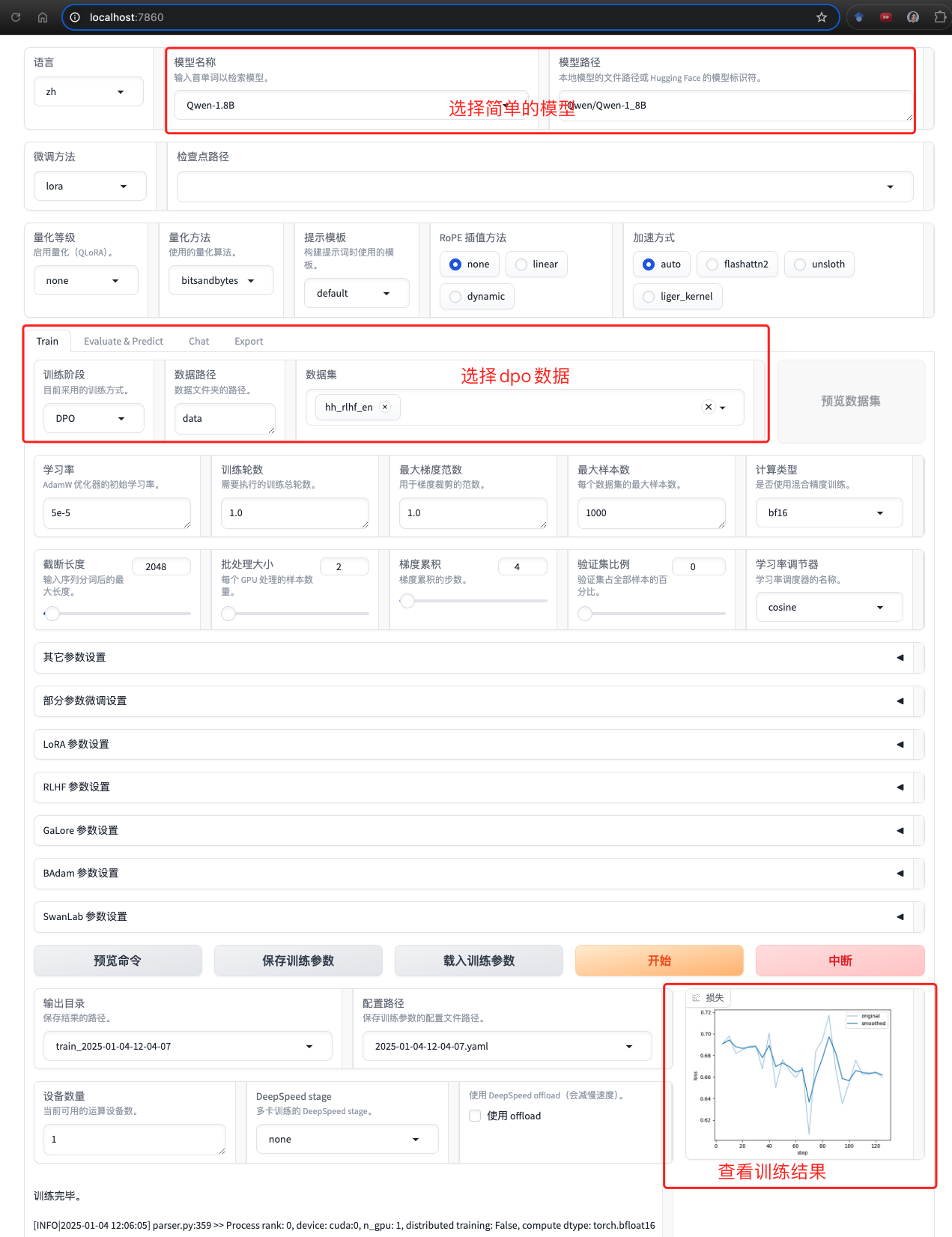
这个训练过程简直就是一场视觉盛宴!
- Loss 曲线平滑下降,就像一个优雅的舞者
- 学习率的调整精准而富有节奏
- 训练进度条稳步前进,让人心里踏实
- GPU 显存使用情况一目了然,再也不用担心爆显存
更让我觉得贴心的是,WebUI 还贴心地生成了完整的训练命令:
llamafactory-cli train \
--stage dpo \
--do_train True \
--model_name_or_path Qwen/Qwen-1_8B \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template default \
--flash_attn auto \
--dataset_dir data \
--dataset hh_rlhf_en \
--cutoff_len 2048 \
--learning_rate 5e-05 \
--num_train_epochs 1.0 \
--max_samples 1000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--report_to none \
--output_dir saves/Qwen-1.8B/lora/train_2025-01-04-12-04-07 \
--bf16 True \
--plot_loss True \
--trust_remote_code True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--optim adamw_torch \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all \
--pref_beta 0.1 \
--pref_ftx 0 \
--pref_loss sigmoid
这个命令不仅仅是一串参数的组合,它展示了 LlamaFactory 对微调过程的深刻理解:使用 LoRA 降低显存占用,采用较小的学习率避免破坏预训练知识,设置合理的 batch size 和梯度累积步数…每个参数都经过精心调优。
定制化训练:从示例到本地模型
这个预览命令功能真的是太贴心了!有了它,我们就可以轻松地将这个训练过程迁移到自己的本地模型上。我用的是本地的 InternLM2-1.8B 模型,只需要将命令中的模型路径改为本地路径:
llamafactory-cli train \
--stage dpo \
--do_train True \
--model_name_or_path /path/to/internlm2-1.8b \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template default \
--flash_attn auto \
--dataset_dir data \
--dataset hh_rlhf_en \
--cutoff_len 2048 \
--learning_rate 5e-05 \
--num_train_epochs 1.0 \
--max_samples 1000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--report_to none \
--output_dir saves/Qwen-1.8B/lora/train_2025-01-04-12-04-07 \
--bf16 True \
--plot_loss True \
--trust_remote_code True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--optim adamw_torch \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all \
--pref_beta 0.1 \
--pref_ftx 0 \
--pref_loss sigmoid
训练完成后,在 saves/internlm2-1.8b/lora/dpo_train/ 目录下生成了训练结果:
-
training_loss.png:训练损失曲线 -
training_rewards_accuracies.png:奖励和准确率曲线 -
adapter_model.safetensors:训练得到的 LoRA 权重 - 其他配置文件和中间检查点
训练损失曲线:
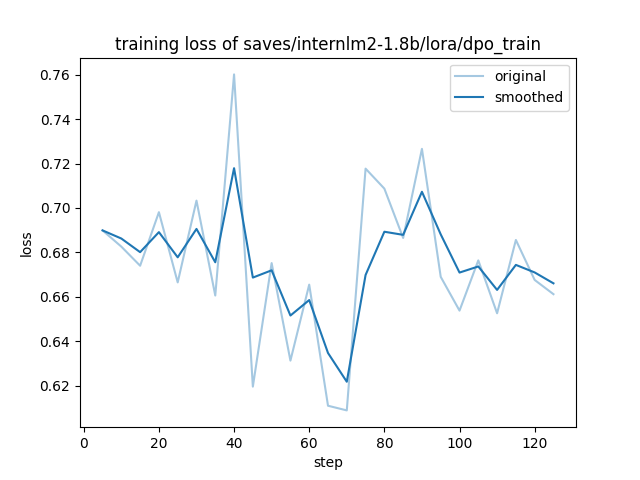
LlamaFactory 确实是一个非常好用的工具,它让模型微调变得如此简单。通过实践我发现,它的 WebUI 不仅让操作变得直观,更重要的是帮助我们理解了微调过程中的各个参数和步骤。不过需要注意的是,在实际使用中,数据质量和模型选择仍然是最关键的因素。工具再好,也要有优质的数据和合适的基座模型才能训练出好的效果。更多解读理解文档请参考 link。
Enjoy Reading This Article?
Here are some more articles you might like to read next: